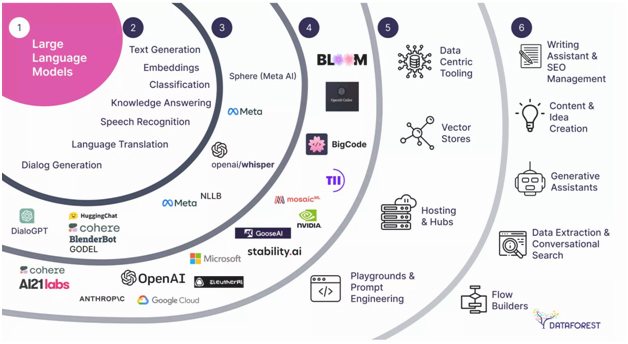
Large Language Models (LLMs) are a type of AI model designed to understand and generate human-like text. They are typically based on transformer architectures, such as the GPT (Generative Pre-trained Transformer) series, which processes language by learning patterns, context, and structures within vast datasets. These models are pre-trained on extensive text data, allowing them to generate coherent and contextually relevant responses to a wide variety of prompts.
Modern LLMs like GPT-4 are used in applications such as conversational agents, content creation, code generation, language translation, and more. They continuously improve through innovations in training techniques, data handling, and integration with other AI models (like reinforcement learning).
Key components of LLMs include:
- Architecture: Based on transformers, they rely on self-attention mechanisms, enabling them to process and relate information across large text sequences.
- Pre-training: LLMs undergo pre-training on a vast corpus to learn grammar, facts, reasoning patterns, and even nuances of various topics.
- Fine-tuning: Many LLMs are fine-tuned for specific applications or with human feedback to improve relevance, reduce bias, and align outputs with user needs.
- Tokenization: Text inputs are broken down into smaller units (tokens), allowing the model to process and predict each part of a sequence effectively.
- Context Windows: LLMs have a limited context window, meaning they can only “remember” a certain amount of prior text, which affects how they generate coherent and contextually accurate responses over long passages.
In the context of prompt engineering, Large Language Models (LLMs) are used to generate responses based on the prompts they receive. Some of the most commonly used LLMs include:
Common LLMs for Prompt Engineering:
1. GPT (Generative Pre-trained Transformer): This includes versions like GPT-3 and GPT-4 by OpenAI, which are widely used for natural language generation and understanding tasks.
2. BERT (Bidirectional Encoder Representations from Transformers): A model by Google focused more on understanding the meaning of sentences in context, often used for comprehension tasks rather than generation.
3. T5 (Text-To-Text Transfer Transformer): A model by Google that treats every NLP task as a text-to-text problem, such as translation, summarization, and question answering.
4. BLOOM: An open-source LLM trained to understand and generate text in multiple languages.
5. LLaMA (Large Language Model Meta AI): Developed by Meta, this model is designed for efficiency and optimized performance, often used in prompt-based tasks.
6. Claude by Anthropic: A language model designed to generate responses and assist with complex natural language tasks.
While all these models are capable of interacting through prompts, GPT-based models (like GPT-4 or GPT-3.5) are particularly popular for tasks that involve generating and interpreting responses based on complex, user-defined instructions (prompts).
How to Make LLM-Based Prompt Engineering More Efficient
To improve the efficiency of prompt engineering with LLMs, there are various strategies that can be employed. These fall into several categories, including optimizing the model’s performance, reducing latency, increasing accuracy, and ensuring relevance in responses.
1. Crafting More Effective Prompts
- Be Clear and Specific: The clearer and more specific your prompt is, the more likely the model is to provide accurate and efficient responses.
- Example: Instead of asking, “Explain AI,” ask, “Explain the difference between supervised and unsupervised learning in AI with examples.”
- Contextualize the Request: Add context so the model understands the background or situation, making it more likely to produce a relevant answer.
- Example: “As a marketing manager, how can AI improve customer engagement?”
- Use Examples or Templates: Provide examples in the prompt to guide the model toward the type of answer you want.
- Example: “Create a product description for a smartwatch, similar to this: [insert template].”
2. Using Prompt Chaining for Complex Tasks
- Break Down the Query: For complex tasks, break the prompt into smaller, manageable steps, using prompt chaining.
- Example:
- Step 1: “Summarize the main points of this article.”
- Step 2: “Now, explain the challenges mentioned in the article.”
- Ensure Continuity: When splitting prompts, make sure the follow-up prompts reference earlier results, so the model builds on prior context.
3. Leverage Fine-Tuning and Transfer Learning
- Fine-Tune Models: Fine-tuning the LLM on specific domain-related data can make it more efficient for tasks in that domain. For example, fine-tuning a general model on medical data will make it better suited for healthcare-related queries.
- OpenAI Fine-Tuning: OpenAI’s GPT models allow fine-tuning on custom datasets to adapt the model to specific requirements.
- Transfer Learning: Use pre-trained models that are already trained on related tasks and then fine-tune them on more specific tasks to improve performance.
4. Context Window Optimization
- Context Window Management: Since LLMs have a limited number of tokens they can process (context window), ensure that only the most relevant parts of the document or prompt are included. Remove irrelevant information and structure the input to maximize efficiency.
- Example: If analyzing a lengthy document, divide it into sections and query one section at a time, feeding only the relevant section into the prompt.
- Summarization: Use summarization prompts to distill large amounts of text before performing more specific extraction tasks.
5. Use of Token-Efficient Prompts
- Minimize Token Usage: LLMs process text as tokens, and shorter, more concise prompts reduce the computational load. Aim to formulate your queries in a token-efficient way, without sacrificing clarity.
- Example: Instead of “Could you possibly explain how I might improve my website traffic using SEO?” use “Explain how to improve website traffic using SEO.”
- Avoid Repetition: Ensure that you’re not repeating unnecessary instructions, which can waste tokens and reduce efficiency.
6. Prompt Libraries and Reusability
- Reusing Effective Prompts: Once you’ve crafted prompts that work well for specific tasks, store them and reuse them. Creating a library of optimized prompts allows for more efficient querying.
- Templates for Common Tasks: Develop template prompts for common tasks like summarization, information extraction, or answering FAQs. This cuts down on the need for re-crafting prompts each time.
7. Multi-Modality and Preprocessing
- Preprocess Inputs: Preprocess documents, emails, or reports by segmenting them or extracting relevant sections before inputting them into the LLM. This reduces the need for the model to process unnecessary or redundant information.
- Multi-Modality: In cases where both text and data (e.g., tables, graphs) are required, preprocess these into text-based formats or provide clear instructions for handling different media types.
8. Use Negative Prompting
- Avoid Unwanted Information: Use negative prompts to instruct the model to avoid certain topics or focus only on relevant areas.
- Example: “Explain the benefits of AI in healthcare, but do not discuss AI ethics.”
9. Use Model APIs Efficiently
- Batch Queries: Instead of sending multiple single requests to the model, batch similar queries together to reduce API calls and improve latency.
- Example: Ask the model to summarize several sections of a document at once, instead of one section per request.
- Experiment with Parameters: Tuning parameters like temperature, max tokens, and top-p can help make responses more focused and concise, especially when generating content.
- Lower Temperature: If you want more deterministic and concise responses, lower the temperature parameter. This will reduce randomness in the model’s output.
10. Post-Processing and Validation
- Validate Output: Use post-processing steps to validate or cross-check the model’s responses. This can involve:
- Automating fact-checking for generated outputs.
- Comparing the response to known standards or other sources.
- Automated Tools: Incorporate validation tools to assess the output quality, flagging potential errors or irrelevant content.
Summary of Key Areas for Efficiency
- Optimize prompt clarity by making instructions precise and using examples.
- Use prompt chaining for complex tasks, breaking down queries into steps.
- Fine-tune models on specific domain datasets for enhanced performance.
- Manage the context window by limiting irrelevant input and focusing on key sections.
- Reduce token usage in prompts by avoiding redundancy and using concise language.
- Develop a library of reusable prompt templates to streamline common tasks.
- Preprocess input data to simplify the information before querying the model.
- Batch similar queries and experiment with API parameters for optimized performance.
By applying these strategies, you can significantly improve the efficiency and effectiveness of prompt engineering when working with LLMs.